As I wrote on my previous post, KEDA 2.6 includes the first iteration of a Datadog scaler. In this post I will show an end-to-end example on how to use KEDA and Datadog metrics to drive your scaling events.
Deploying KEDA
I am starting with a clean Kubernetes cluster, so the first thing that needs to be done is to deploy KEDA in our cluster. I used Helm for this, and basically followed KEDA documentation for this.
Once KEDA is deployed in the cluster, the following two deployments get deployed to the keda namespace:
NAME READY UP-TO-DATE AVAILABLE AGE
keda-operator 1/1 1 1 49m
keda-operator-metrics-apiserver 1/1 1 1 49m
The keda-operator will be the controller for your ScaledObjects and TriggerAuthentications objects and will drive the creation or deletion of the corresponding HPA objects. The keda-operator-metrics-apiserver will implement the Custom Metrics Server API, that the HPA controller will use to get the needed metrics to drive the scaling events.
The Datadog Helm chart, by default, deploys three workloads: the Datadog Node Agent, the Datadog Cluster Agent, and Kube State Metrics by default. Kube State Metrics is a service that listens to the Kubernetes API and generates metrics about the state of the objects. Datadog uses some of these metrics to populate its Kubernetes default dashboard.
Deployments:
NAME READY UP-TO-DATE AVAILABLE AGE
datadog-cluster-agent 1/1 1 1 5s
datadog-kube-state-metrics 1/1 1 1 1m
Daemonsets:
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
datadog 1 1 1 1 1 kubernetes.io/os=linux 22h
Our target deployment
To try the Datadog KEDA scaler we are going to create an NGINX deployment and enable Datadog’s NGINX integration, to start sending relevant metrics to Datadog. You can have a look to the YAML definition we will use for this.
After deploying this, we will have 1 NGINX replica running on our cluster:
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 1/1 1 1 2m58s
Authenticating our Datadog account in KEDA
KEDA will be using our Datadog account to gather the needed metrics to make its scaling decisions. For that, we need to authenticate our account to KEDA.
First, let’s create a secret that contains our Datadog API and App keys (this command assumes you have exported your keys to the environment variables DD_API_KEY and DD_APP_KEY):
The way KEDA manages authentication to the different scaler providers is through a Kubernetes object called TriggerAuthentication. Let’s create one for our Datadog account:
We are going to tell KEDA to autoscale our NGINX deployment based on some Datadog metric. For that, KEDA uses another custom object called ScaledObject. Let’s define it for our NGINX deployment and the Datadog metric we care about:
We are telling KEDA to scale our nginx deployment, to a maximum of 3 replicas, using the Datadog scaler, and to scale up if the average requests per second per NGINX pod is over 2, in the past 60 seconds.
Once you create the ScaledObject, KEDA will create the corresponding HPA object for you:
kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-datadog-scaledobject Deployment/nginx 0/2 (avg) 1 3 1 44s
Forcing the scaling event
Let’s “force” the scaling event by increasing the number of requests to NGINX in our cluster. You can force this by creating a deployment that continously creates requests to the NGINX service:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-datadog-scaledobject Deployment/nginx 0/2 (avg) 1 3 1 22m
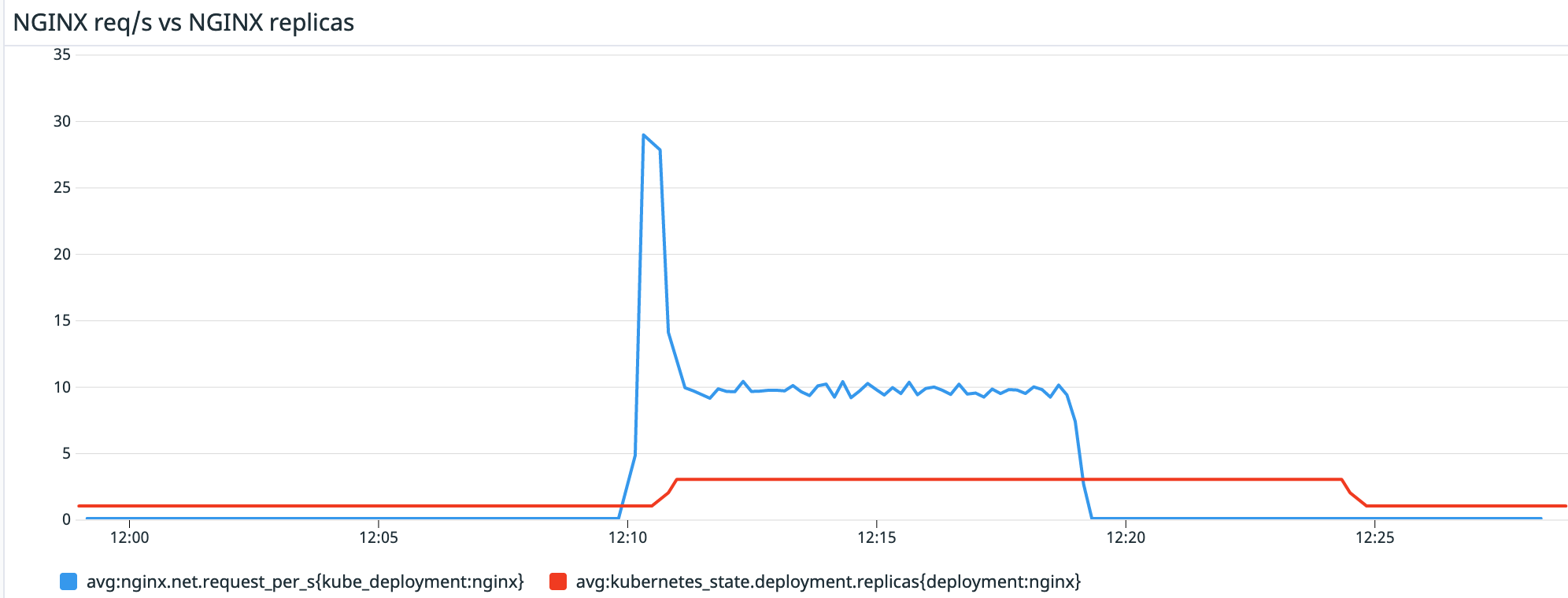
If we check in Datadog, we can easily graph and visualize the correlation between the number of requests the nginx deployment is getting and the number of replicas it has. We also see the 5 minute cooldown period:
Summary
KEDA version 2.6 includes a new Datadog scaler that can be used to drive horizontal scaling events based on any metric available in Datadog. On this blog post we saw a simple example on how to use the Datadog scaler to drive scaling an NGINX deployment, based on the number of requests the service is getting.
KEDA is a Kubernetes based Event Driven Autoscaler. It allows driving the horizontal pod autoscaling of any deployment in Kubernetes, acting as an Metrics Server for the Horizontal Pod Autoscaler.
What makes KEDA interesting is that it has a pluggable architecture, so there are a large (and increasing) number of “scalers” to choose from to drive your scaling events. KEDA scalers allow you to drive your scaling events based on a different types of events, like an AWS SQS queue length, or an Apache Kafka topic.
If you need to gather events from different sources for your scaling events, using KEDA might be a good option, as, currently, there is a limitation of one custom metric server per Kubernetes cluster.
Introducing the Datadog KEDA scaler
When I was researching this project, I realized that there wasn’t yet a Datadog scaler, and thought that it would be a fun project to hack on, and learn how KEDA works in the process. KEDA community was very helpful and welcoming, and they provided very useful feedback while I was working on the PR.
Available since KEDA 2.6, there is a Datadog KEDA scaler, so you can use KEDA to drive scaling events based on any Datadog metric, allowing to express a full Datadog query in the trigger specification:
The Datadog KEDA scaler uses Datadog’s public API to retrieve the metrics that will then be used to update the corresponding HPA object, created and managed by KEDA.
Right now the KEDA scaler for Datadog can only drive scaling events based on metric values, but in the future it could be expanded to scale based on events, monitor status, etc.
Datadog’s Cluster Agent Custom Metrics Server
Even though there is now a Datadog KEDA scaler that can be used, the default, official, HPA implementation for Datadog continues to be the Cluster Agent.
KEDA version 2.6 includes a new Datadog scaler that can be used to drive horizontal scaling events based on any metric available in Datadog. I will write a follow up blog post with a step by step how to use the Datadog KEDA scaler with a real example.
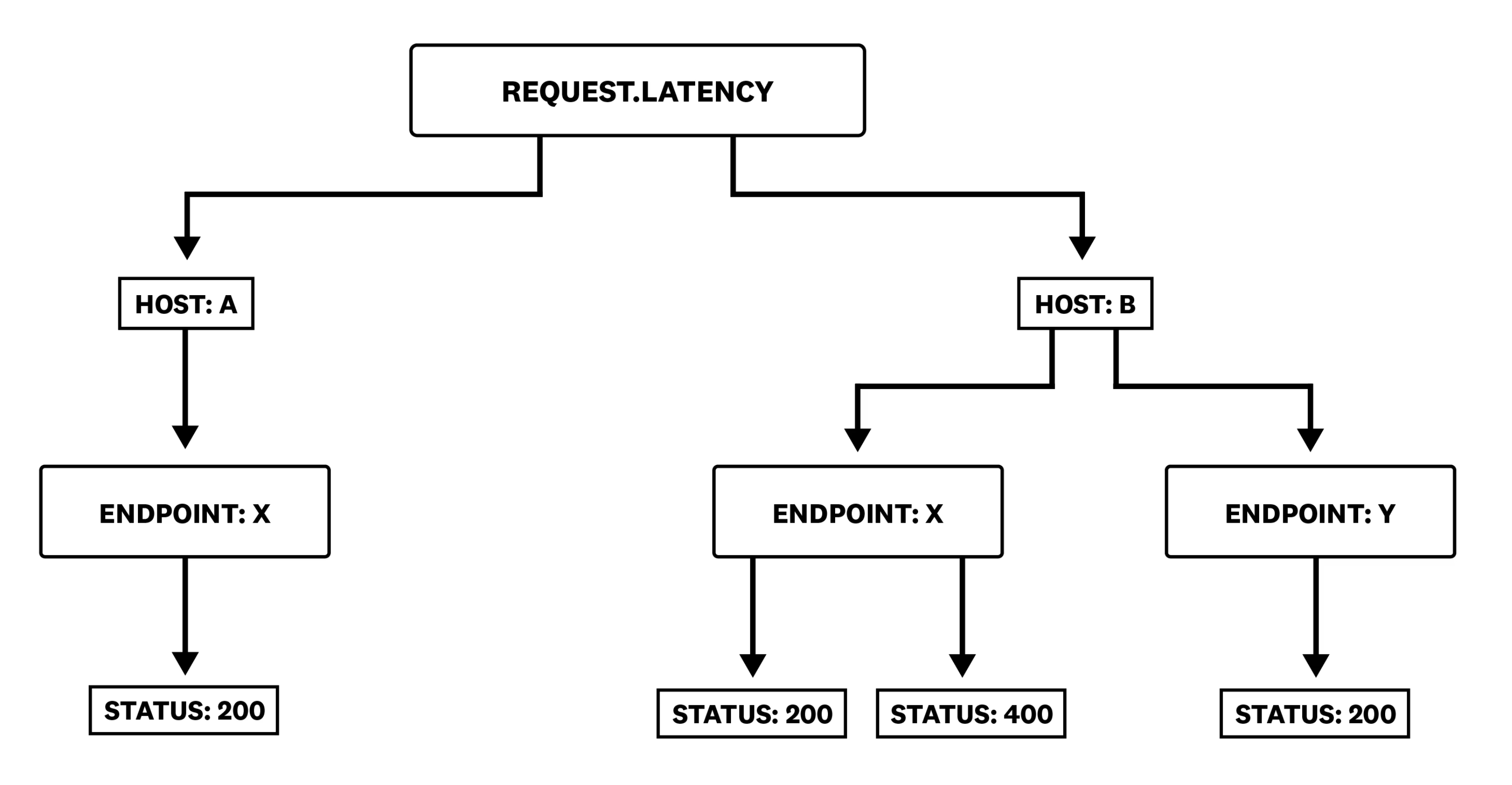
When metrics are emitted, each of the values of a particular metric are sent with a set of tags. Depending on the tags that a metric emits, you can filter and/or aggregate by those, allowing slicing and dicing the data as needed in order to discover information.
The cardinality of a metric is basically the number of tags and possible values of each of those tags. An example of a low cardinality tag could be region, if the potential values for that tag are only APAC, EMEA and AMER. An example of a high cardinality (potentially infinite!) tag could be something like customer_id, as there is no limit in the potential values of that tag.
There are two main reasons why trying to get granularity right is a good idea:
If you add a high-cardinality tag to your metric, but that tag is not really adding information to the metric (i.e. you don’t care the specific customer, you only care about aggregated data, like country), it will clutter your metrics (and the Datadog UI).
To make things easier, the Datadog agent in Kubernetes collects a set of tags related to your Kubernetes environment, like kube_deployment, kube_service, cluster_name, etc. These are tags that will be relevant for almost any metric emitted from Kubernetes.
But there are tags that the agent collects that can increase the cardinality of a metric, for example, pod_name. pod_name is a tag with a very high cardinality, as pods are ephemeral, and when part of a Deployment or Daemonset, they take a different name every time they get rescheduled.
To make sure that the user is in control of what tags to emit, the set of tags that are sent by default by the agent is configurable, using the environment variables DD_CHECKS_TAG_CARDINALITY and DD_DOGSTATSD_TAG_CARDINALITY. These variables take the values of low, orchestrator, high and default to low. pod_name, for example, is only emitted for a check if DD_CHECKS_TAG_CARDINALITY is set to orchestrator or high.
But if the default is low, why am I seeing some metrics emitting pod_name?
There are several integrations that override the default cardinality value, as for the type of metrics they emit, they require a set of tags to really be useful.
The Datadog Kubernetes agent attaches some out-of-the-box tags to the metrics it emits, but high cardinality tags are only sent if the user modifies the agent configuration. Before modifying these options it is important to understand the consequences, including a potential increase of custom metrics.
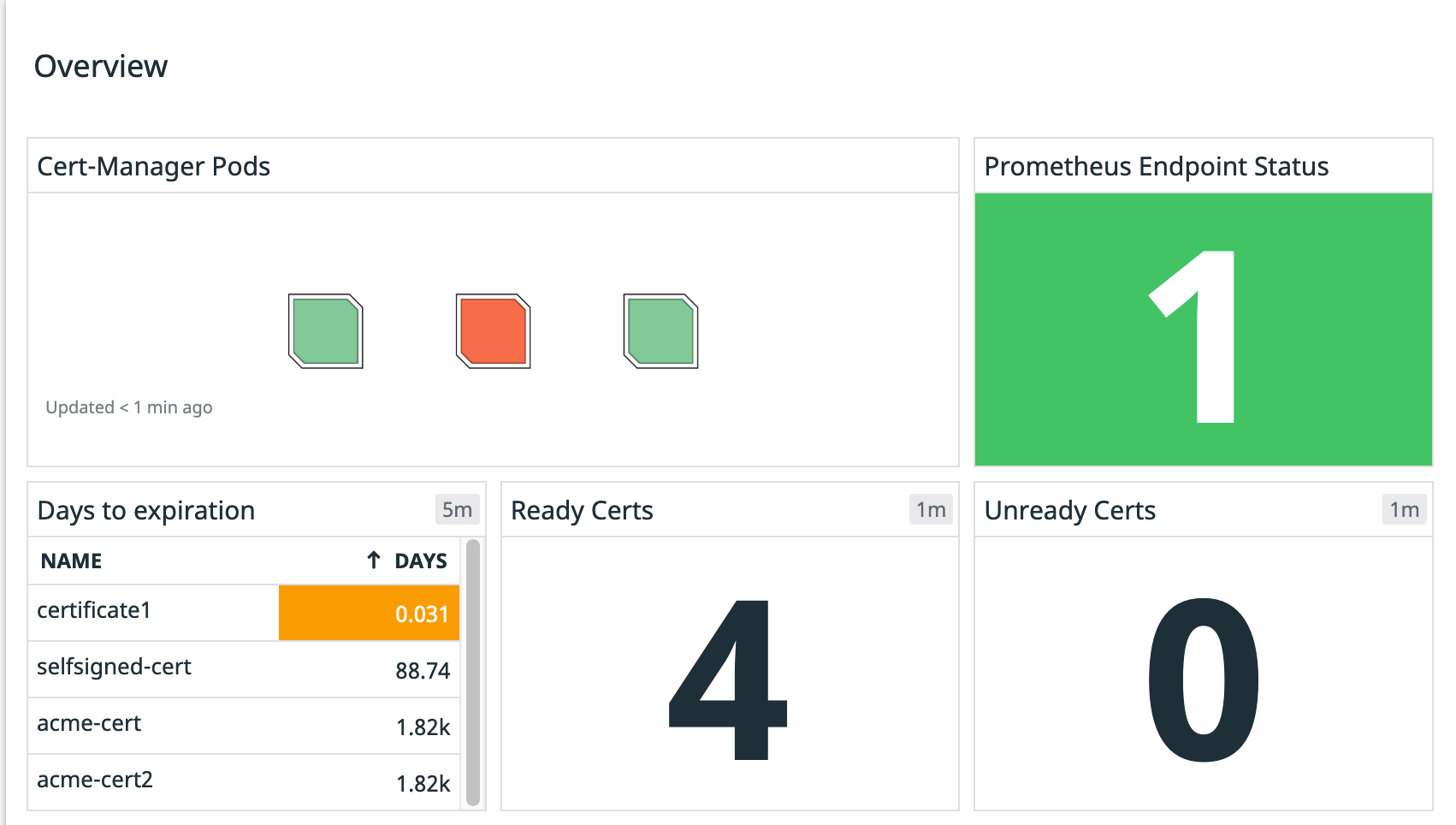
Datadog cert-manager integrationversion 2.2.0 includes a new widget in its default dashboard that gets the days to expiration for each certificate in your clusters, color-coding the ones close to expiration:
If you are using the cert-manager integration, make sure to update it to its latest version to get this new widget to populate correctly. If you are not using the integration and/or want to learn more about the certmanager_clock_time_seconds metric, continue reading.
certmanager_clock_time_seconds
cert-manager 1.5.0 introduced a new metric, certmanager_clock_time_seconds that returns the timestamp of the current time. Thanks to this new metric, we are able to calculate the time left before the expiration of the certificate, thanks to the existance of the certmanager_certificate_expiration_timestamp_seconds metric.
The problem is that when certmanager_clock_time_seconds metric was added, it was added as a counter, where it should have been a gauge. If this metric is a counter, it gets converted to a Datadog monotonic counter, and Datadog only offers the delta between the previous reported value and the current value, making the metric value of the timestamp pretty useless.
Fortunately, Datadog offers overriding its OpenMetrics default mapping, so we are able to fix this on Datadog’s side, while it gets fixed upstream.
If you are using the OpenMetrics integration, you can override this metric to be a gauge by adding the following annotations in your cert-manager deployment (adding other metrics you want to add as well):
If you are using the Datadog cert-manager integration, this mapping is already done for you, if you are using version 2.2.0 or newer of the integration.
Calculating time to expiration for a certificate
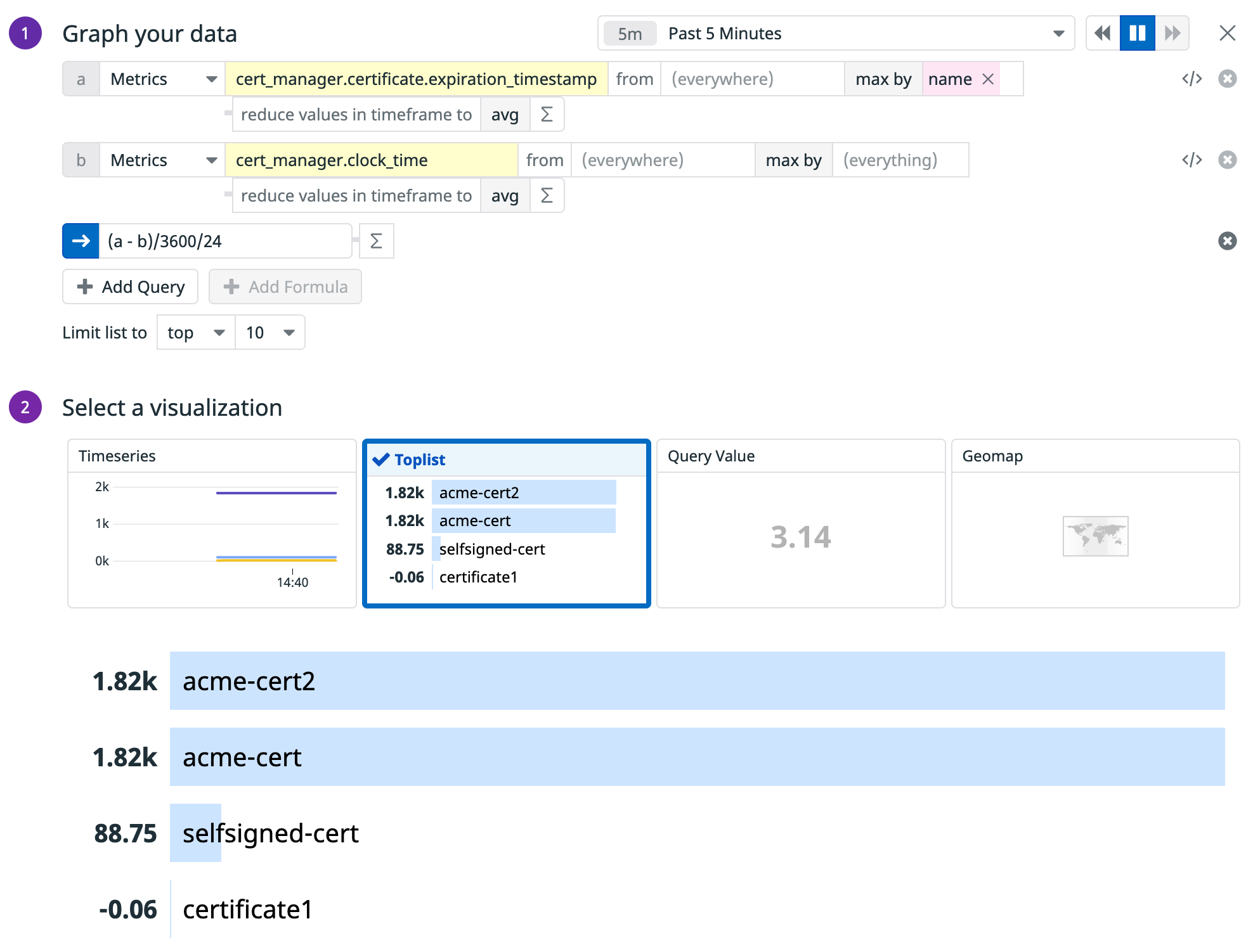
Once we have the certmanager_clock_time_seconds metric correctly reporting as a gauge in Datadog, we are able to start calculating the time to expiration of any given certificate. As an example, let’s create a widget that gets the list of certificates, ordered by days to expiration.
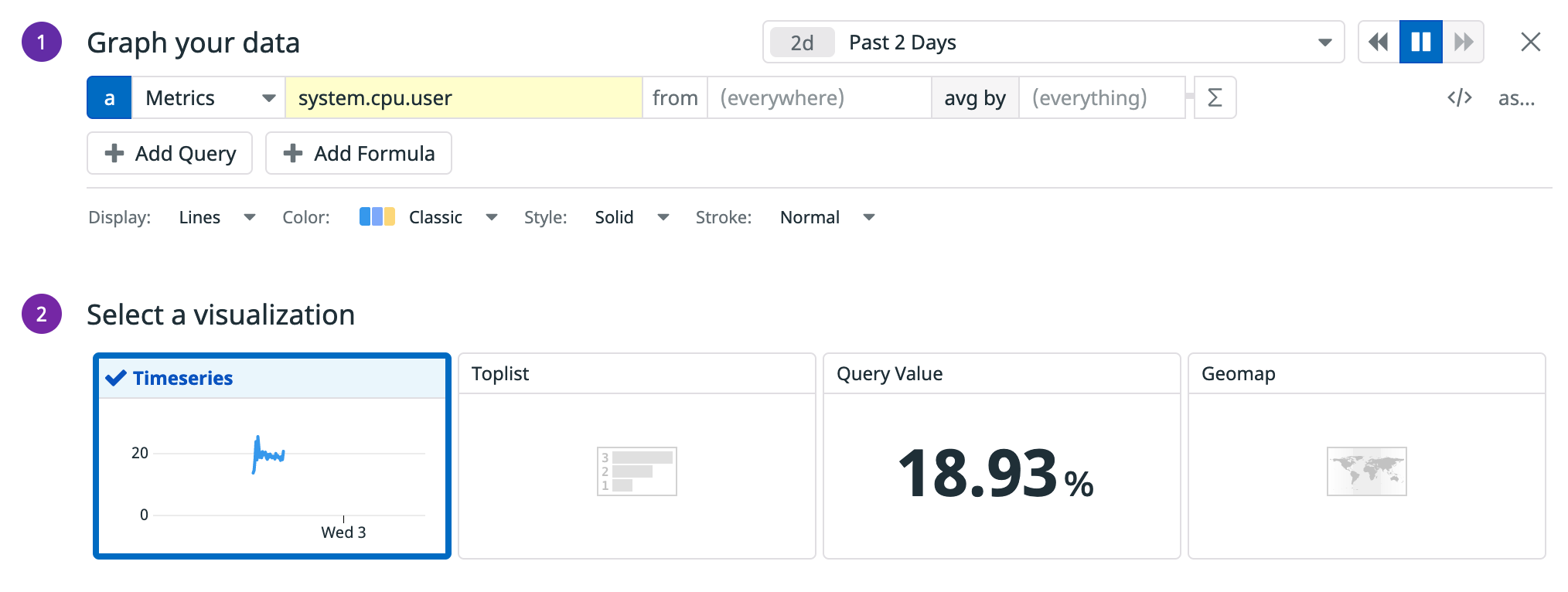
Typing G in our Datadog environment, the Quick Graph modal open:
For the type of widget, select “Top List” and create the following formula:
You will get the number of days for your certificates to expire. This same visualization is already part of the Cert Manager Overview default Dashboard:
Conclusion
Thanks to the addition of the certmanager_clock_time_seconds metric to the OpenMetrics exporter from cert-manager, we are now able to make calculations related to other timestamp metrics in cert-manager.
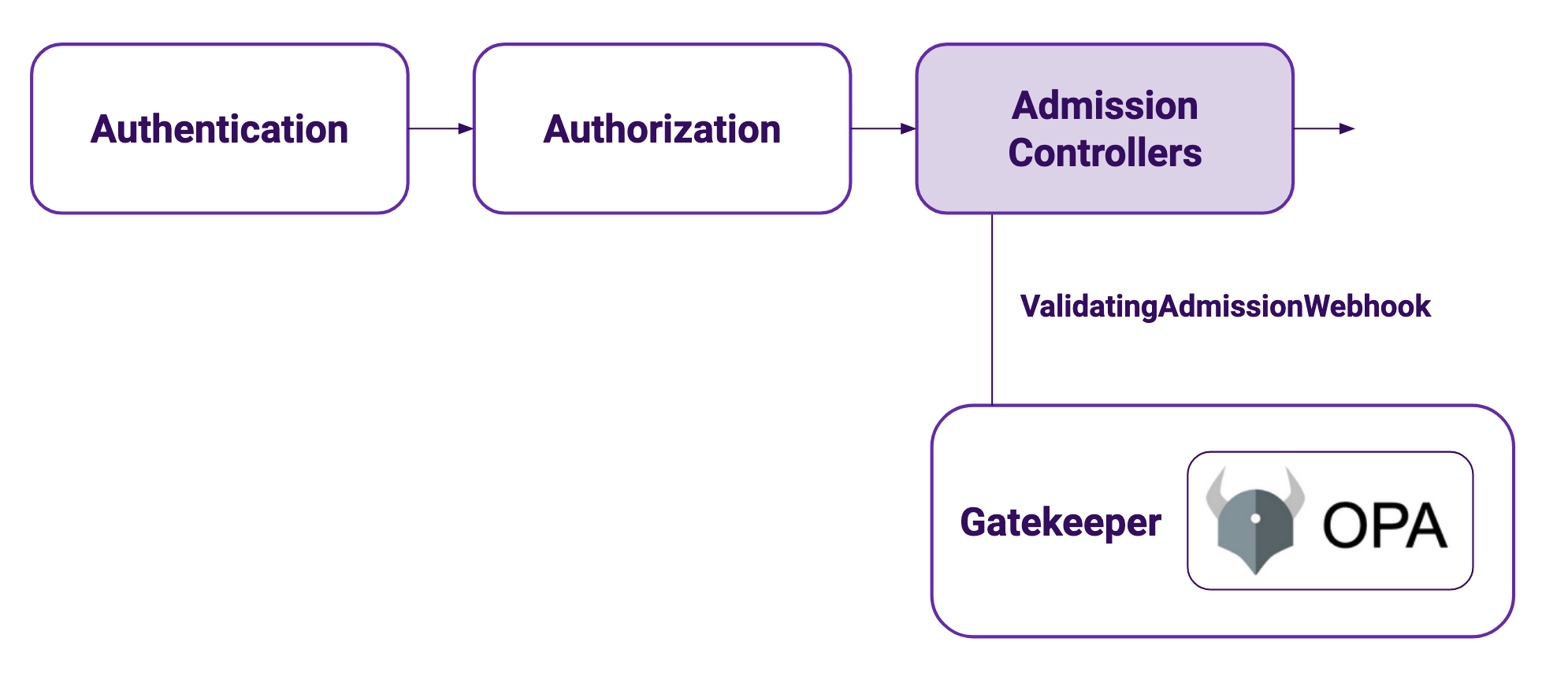
Gatekeeper is a CNCF project, part of Open Policy Agent, that enforces OPA policies in Kubernetes clusters through an Admission Controller Webhook.
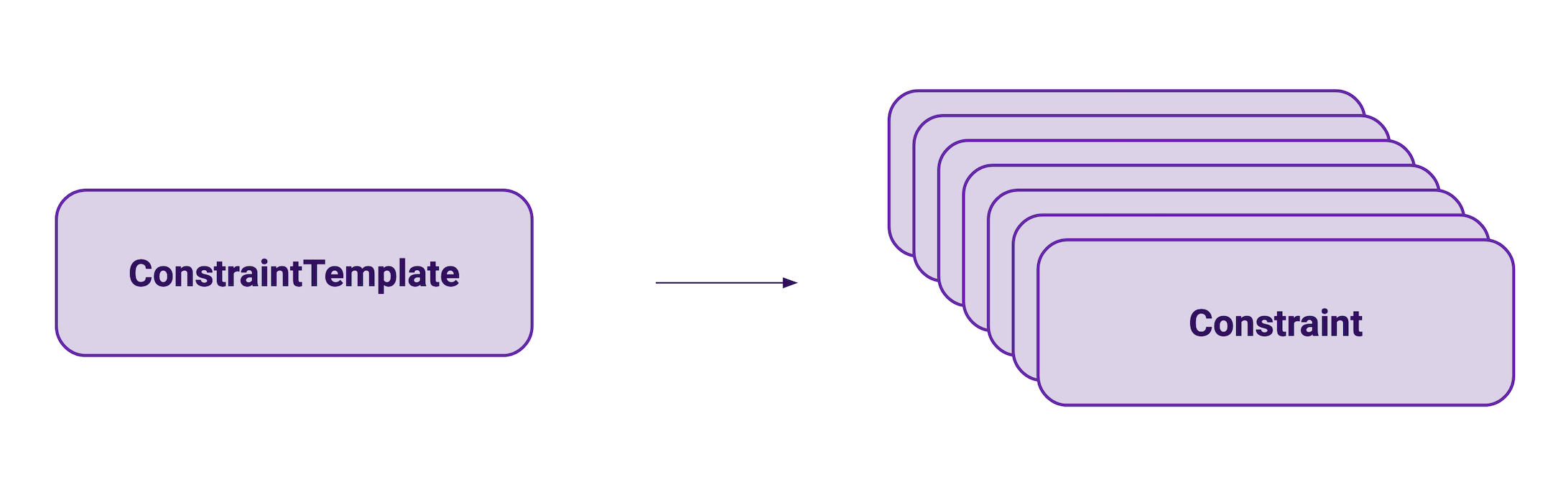
Once you have the Gatekeeper controller running in your cluster, you can start writing reusable policies for your cluster through a CustomResourceDefinition object called ConstraintTemplate. These objects contain the policy code written in Rego, a domain specific language for OPA. These ConstraintTemplates are not policies themselves, but parametrized templates that then get instantiated into policies through Constraint objects.
This post assumes that you are familiar with using Gatekeeper in your Kubernetes cluster, as we will be focusing on how to enable it in a CI loop. If you need to learn more about Gatekeeper and how to enable it in your cluster I would recommend you to read the official documentation.
Testing your policies as part of CI
This is great, but the following question would be: if I am following a GitOps process for my Kubernetes cluster and all my configuration changes got through a pull request and get committed to a git repository before they get applied to my cluster, how can I also test my configuration against my company policy automatically as part of CI to avoid trying to apply objects that will be rejected?
OPA has a project called conftest that enables staticly testing a set of Rego policies against structured data, including YAML description files. The problem with using conftest if you are writing your policies for Gatekeeper is that you will need to maintain two sets of policies: the ones parametrized as ConstraintTemplates and a set of fully written Rego policies that already have the different parameters you have created.
For this reason, if your mainly using OPA with Gatekeeper I would recommend to test your policies against a lightweigth Kubernetes cluster, like kind, and test against your real policies as part of your CI loop.
Gatekeeper hooks to the ValidationAdmissionWebhook, part of the Kubernetes API server. When a request gets to the API server it goes through authentication, then authorization and then through the list of admission controllers. If the request doesn’t follow your cluster policy, it will be rejected at that point. This means that using a server side dry run of the request (available since Kubernetes 1.13) is enough to test your policies, without needing to really apply the objects, making your test pipelines a lot faster.
Using GitHub Actions with a sample repository
As an example on how this could be implemented in the CI tool of your choice, we will be using a sample GitHub repository and GitHub Actions for our CI pipeline. The repository, called gatekeeper_testing is open source and can be found at: https://github.com/arapulido/gatekeeper_testing/.
kubernetes-config includes all the Kubernetes objects we deploy in our sample cluster
policies/constrainttemplates includes the Gatekeeper constraint templates we have in our sample cluster
policies/constraints includes the Gatekeeper constraints we have in our sample cluster
We are assuming that kubernetes-config is the configuration we want to apply in our cluster and that, following GitOps best practices, new or modified objects will be committed to this repository before applying them to our cluster.
To test that any changes made to the objects are allowed by our Gatekeeper policies we create a GitHub Actions workflow that will test any changes to the repository against the policy:
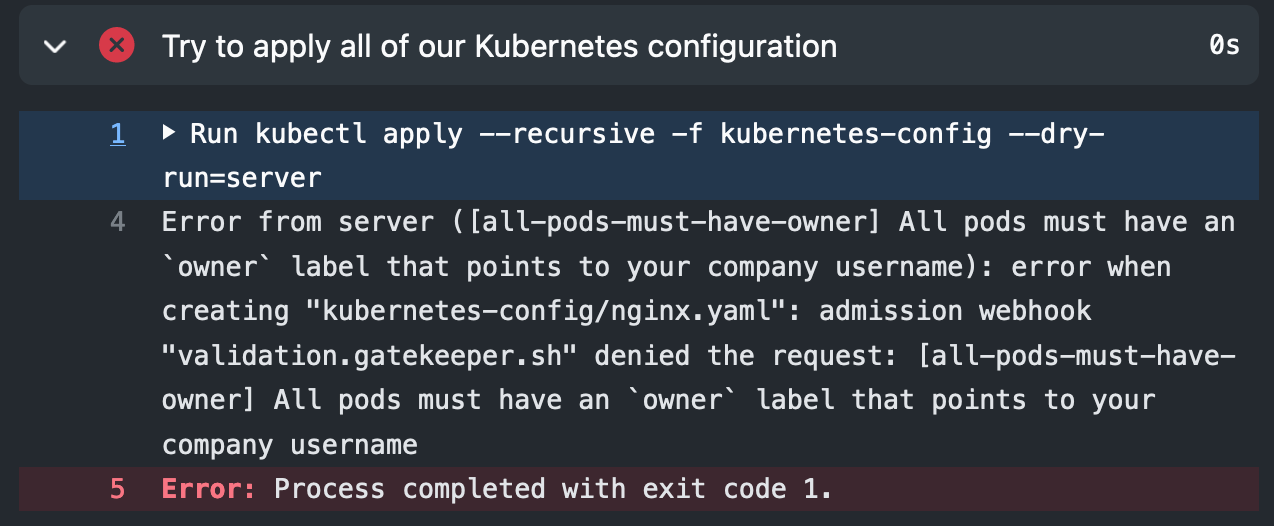
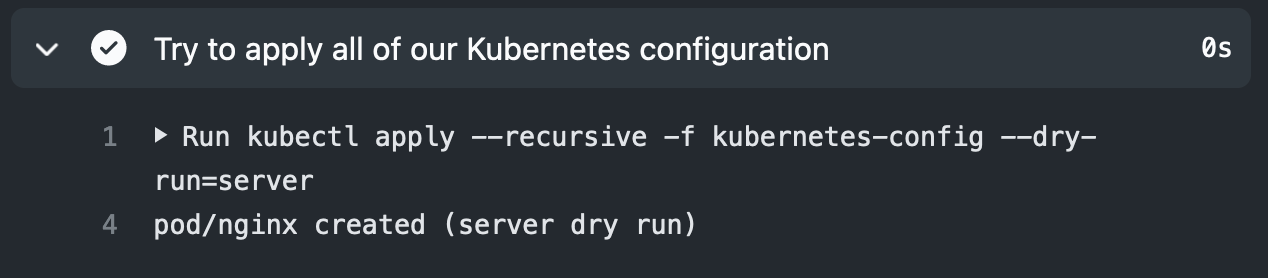
name:Test Kubernetes objects against Gatekeeper policieson:pushjobs:test-policies:runs-on:ubuntu-lateststeps:-name:Checkoutuses:actions/checkout@v2with:fetch-depth:0-name:Install kubectluses:azure/setup-kubectl@v1id:install-name:Create kind clusteruses:helm/kind-action@v1.2.0-name:Deploy Gatekeeper 3.5run:kubectl apply -f https://raw.githubusercontent.com/open-policy-agent/gatekeeper/release-3.5/deploy/gatekeeper.yaml-name:Wait for Gatekeeper controllerrun:kubectl -n gatekeeper-system wait --for=condition=Ready --timeout=60s pod -l control-plane=controller-manager-name:Apply all ConstraintsTemplatesrun:kubectl apply --recursive -f policies/constrainttemplates/-name:Waitrun:sleep 2-name:Apply all Constraintsrun:kubectl apply --recursive -f policies/constraints/-name:Waitrun:sleep 2-name:Try to apply all of our Kubernetes configurationrun:kubectl apply --recursive -f kubernetes-config --dry-run=server
After creating the Kubernetes cluster, deploying Gatekeeper and applying the policy, in the last step we try to create all of our Kubernetes configuration, but using a server side dry-run (the objects that follow the policy won’t be really created, making the pipeline faster):
-name:Try to apply all of our Kubernetes configurationrun:kubectl apply --recursive -f kubernetes-config --dry-run=server
In this blog post we have seen how Gatekeeper policies can be integrated in a CI loop to be able to test new or modified Kubernetes objects against policy using a lightweight Kubernetes cluster and server side dry runs.
Take into account that having policy checks as part of your CI loop is an addition to having the Gatekeeper controller running in your clusters, and that you should always be running Gatekeeper in your clusters to make sure your company’s policy is being followed.