How to use the Datadog KEDA scaler

Introduction
As I wrote on my previous post, KEDA 2.6 includes the first iteration of a Datadog scaler. In this post I will show an end-to-end example on how to use KEDA and Datadog metrics to drive your scaling events.
Deploying KEDA
I am starting with a clean Kubernetes cluster, so the first thing that needs to be done is to deploy KEDA in our cluster. I used Helm for this, and basically followed KEDA documentation for this.
Once KEDA is deployed in the cluster, the following two deployments get deployed to the keda namespace:
NAME READY UP-TO-DATE AVAILABLE AGE
keda-operator 1/1 1 1 49m
keda-operator-metrics-apiserver 1/1 1 1 49m
The keda-operator will be the controller for your ScaledObjects and TriggerAuthentications objects and will drive the creation or deletion of the corresponding HPA objects. The keda-operator-metrics-apiserver will implement the Custom Metrics Server API, that the HPA controller will use to get the needed metrics to drive the scaling events.
Deploying Datadog
We will deploy the Datadog Agent in the cluster, that will collect the cluster metrics and send them to our Datadog account. I basically follow Datadog’s official documentation on how to deploy the agent using Helm, using the default values.yaml file.
The Datadog Helm chart, by default, deploys three workloads: the Datadog Node Agent, the Datadog Cluster Agent, and Kube State Metrics by default. Kube State Metrics is a service that listens to the Kubernetes API and generates metrics about the state of the objects. Datadog uses some of these metrics to populate its Kubernetes default dashboard.
Deployments:
NAME READY UP-TO-DATE AVAILABLE AGE
datadog-cluster-agent 1/1 1 1 5s
datadog-kube-state-metrics 1/1 1 1 1m
Daemonsets:
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
datadog 1 1 1 1 1 kubernetes.io/os=linux 22h
Our target deployment
To try the Datadog KEDA scaler we are going to create an NGINX deployment and enable Datadog’s NGINX integration, to start sending relevant metrics to Datadog. You can have a look to the YAML definition we will use for this.
After deploying this, we will have 1 NGINX replica running on our cluster:
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 1/1 1 1 2m58s
Authenticating our Datadog account in KEDA
KEDA will be using our Datadog account to gather the needed metrics to make its scaling decisions. For that, we need to authenticate our account to KEDA.
First, let’s create a secret that contains our Datadog API and App keys (this command assumes you have exported your keys to the environment variables DD_API_KEY and DD_APP_KEY):
kubectl create secret generic datadog-secrets --from-literal=apiKey=${DD_API_KEY} --from-literal=appKey=${DD_APP_KEY}
The way KEDA manages authentication to the different scaler providers is through a Kubernetes object called TriggerAuthentication. Let’s create one for our Datadog account:
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: keda-trigger-auth-datadog-secret
spec:
secretTargetRef:
- parameter: apiKey
name: datadog-secrets
key: apiKey
- parameter: appKey
name: datadog-secrets
key: appKey
Autoscaling our NGINX deployment
We are going to tell KEDA to autoscale our NGINX deployment based on some Datadog metric. For that, KEDA uses another custom object called ScaledObject. Let’s define it for our NGINX deployment and the Datadog metric we care about:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: datadog-scaledobject
spec:
scaleTargetRef:
name: nginx
minReplicaCount: 1
maxReplicaCount: 3
pollingInterval: 5
triggers:
- type: datadog
metadata:
query: "avg:nginx.net.request_per_s{kube_deployment:nginx}"
queryValue: "2"
age: "60"
authenticationRef:
name: keda-trigger-auth-datadog-secret
We are telling KEDA to scale our nginx deployment, to a maximum of 3 replicas, using the Datadog scaler, and to scale up if the average requests per second per NGINX pod is over 2, in the past 60 seconds.
Once you create the ScaledObject, KEDA will create the corresponding HPA object for you:
kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-datadog-scaledobject Deployment/nginx 0/2 (avg) 1 3 1 44s
Forcing the scaling event
Let’s “force” the scaling event by increasing the number of requests to NGINX in our cluster. You can force this by creating a deployment that continously creates requests to the NGINX service:
apiVersion: apps/v1
kind: Deployment
metadata:
name: fake-traffic
labels:
app: fake-traffic
spec:
replicas: 3
selector:
matchLabels:
app: fake-traffic
template:
metadata:
labels:
app: fake-traffic
spec:
containers:
- image: busybox
name: test
command: ["/bin/sh"]
args: ["-c", "while true; do wget -O /dev/null -o /dev/null http://nginx/; sleep 0.1; done"]
Once we create the fake traffic, and we wait a bit, we will see the number of NGINX replicas increasing:
kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-datadog-scaledobject Deployment/nginx 8/2 (avg) 1 3 3 7m1s
Let’s remove the fake-traffic deployment, to force scaling down our nginx deployment:
kubectl delete deploy fake-traffic
After waiting for 5 minutes (the default cooldownPeriod), our deployment will scale down to 1 replica:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-datadog-scaledobject Deployment/nginx 0/2 (avg) 1 3 1 22m
If we check in Datadog, we can easily graph and visualize the correlation between the number of requests the nginx deployment is getting and the number of replicas it has. We also see the 5 minute cooldown period:
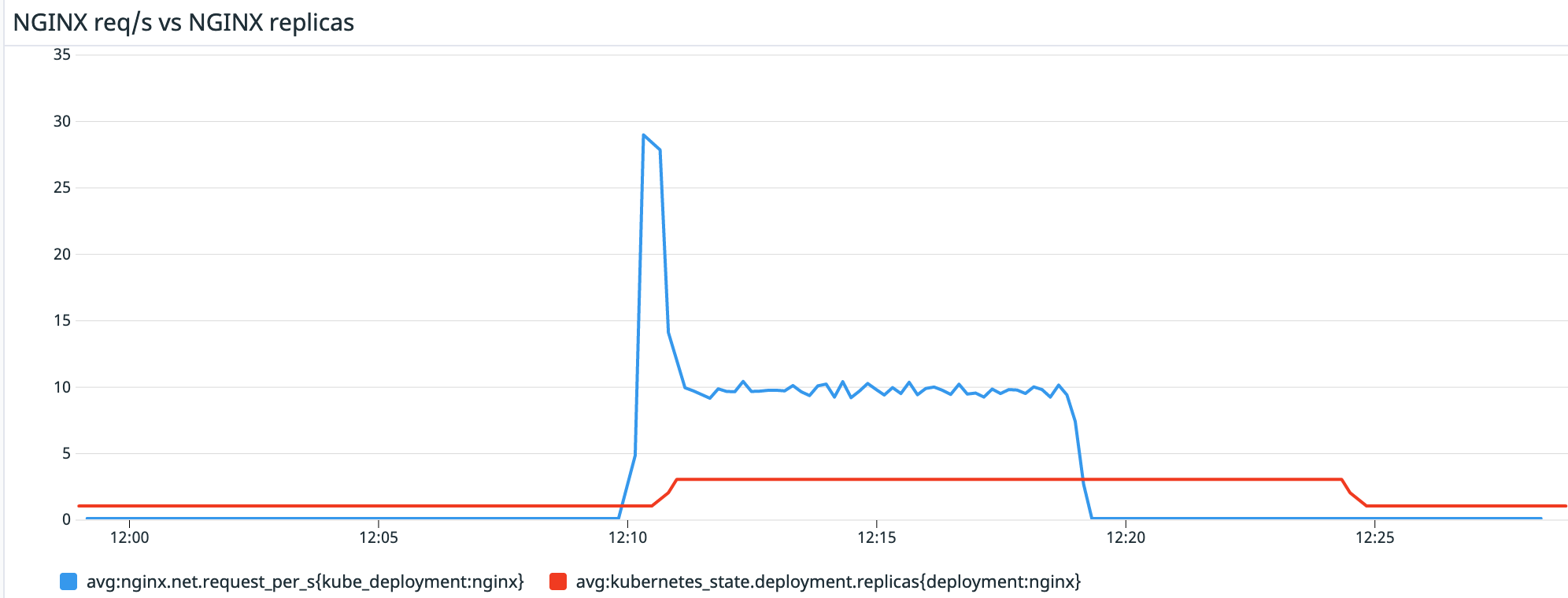
Summary
KEDA version 2.6 includes a new Datadog scaler that can be used to drive horizontal scaling events based on any metric available in Datadog. On this blog post we saw a simple example on how to use the Datadog scaler to drive scaling an NGINX deployment, based on the number of requests the service is getting.