Using the Datadog KEDA scaler with the Cluster Agent as proxy
In February 2022 we introduced the availability of the Datadog KEDA scaler, allowing KEDA users to use Datadog metrics to drive their autoscaling events. This has been working well over the past two years, but it has a main issue, particularly when scaling the number of ScaledObjects that use the Datadog scaler. As the scaler uses the Datadog API to get metrics values, users may reach API rate limits as they scale their KEDA Datadog scaler usage.
For this reason, I decided to contribute again to the KEDA Datadog scaler for it to be able to use the Datadog Cluster Agent as proxy to gather the metrics, instead of polling the API directly. One of the benefits of this approach is that the Cluster Agent is able to batch the metrics requests to the API, reducing the risk of reaching API rate limits.
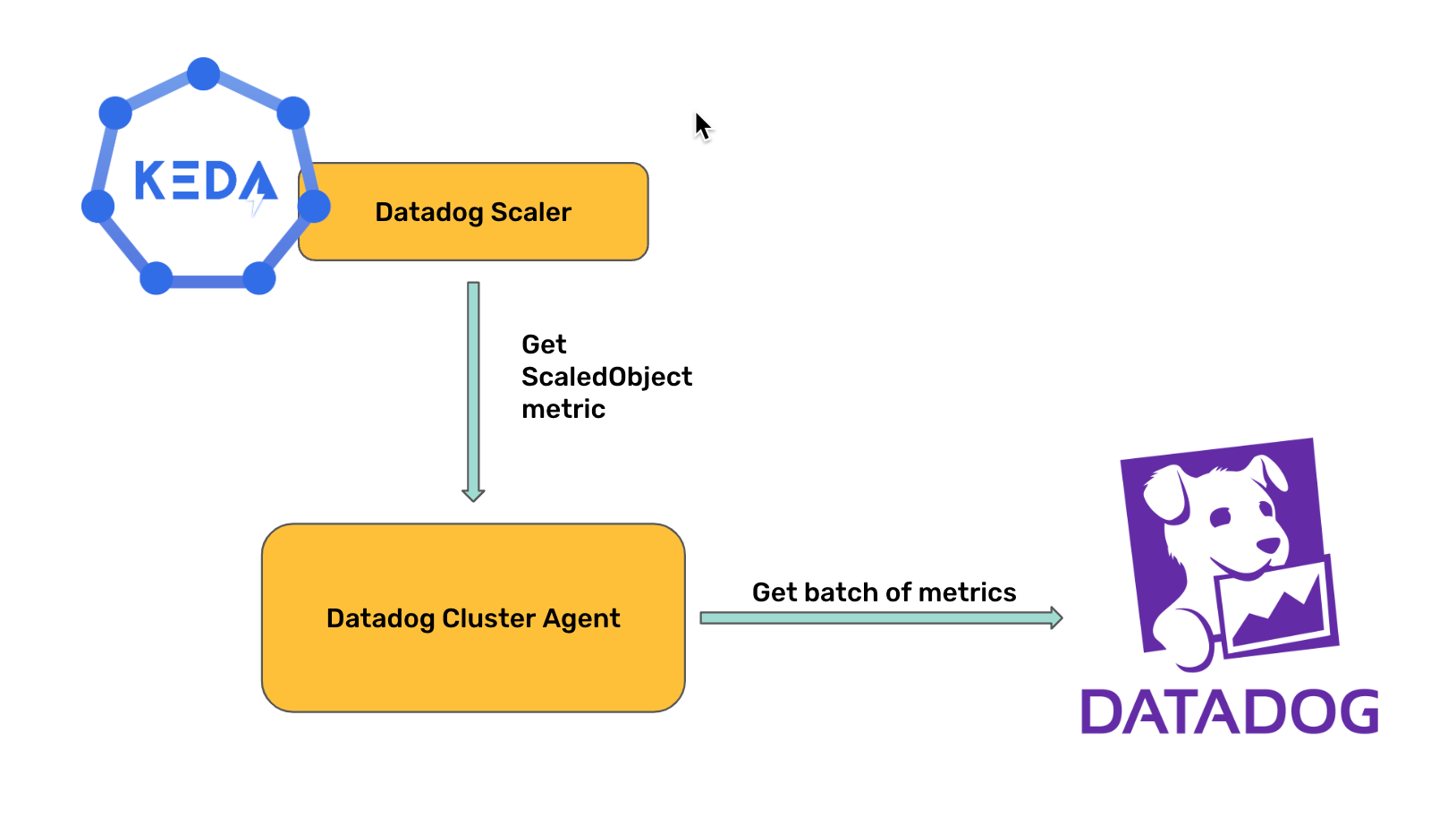
This post will be a step by step guide on how to set up both KEDA and the Datadog Cluster Agent to enable metrics gathering using the Cluster Agent as proxy. In this guide we will be using the Datadog Operator to deploy the Datadog Agent and Cluster Agent, but you can also use the Datadog Helm chart following the KEDA Datadog scaler documentation
Deploying Datadog
We start with a clean simple 1 node Kubernetes cluster.
First, we deploy the Datadog Operator using Helm To use the Cluster Agent as proxy for KEDA, at least version 1.8.0 of the Datadog Operator is needed:
kubectl create ns datadog
helm repo add datadog https://helm.datadoghq.com
helm repo update
helm install my-datadog-operator datadog/datadog-operator --set image.tag=1.8.0 --namespace=datadog
Check that the Operator pod is running correctly:
kubectl get pods -n datadog
NAME READY STATUS RESTARTS AGE
my-datadog-operator-667d4d6645-725j2 1/1 Running 0 2m3s
We will create a secret with our Datadog account API and APP keys:
kubectl create secret generic datadog-secret -n datadog --from-literal api-key=<DATADOG_API_KEY> --from-literal app-key=<DATADOG_APP_KEY>
In order to enable the Cluster Agent as proxy, we will deploy the Datadog Agent with the minimum configuration below:
apiVersion: datadoghq.com/v2alpha1
kind: DatadogAgent
metadata:
name: datadog
namespace: datadog
spec:
global:
kubelet:
tlsVerify: false # This is only needed for self-signed certificates
credentials:
apiSecret:
secretName: datadog-secret
keyName: api-key
appSecret:
secretName: datadog-secret
keyName: app-key
features:
externalMetricsServer:
enabled: true
useDatadogMetrics: true
registerAPIService: false
override:
clusterAgent:
env: [{name: DD_EXTERNAL_METRICS_PROVIDER_ENABLE_DATADOGMETRIC_AUTOGEN, value: "false"}]
Deploy the Datadog Agent and Cluster Agent by applying the definition above:
kubectl apply -f /path/to/your/datadog-agent.yaml
You can check that the Node Agent and Cluster Agent pods are running correctly:
kubectl get pods -n datadog
NAME READY STATUS RESTARTS AGE
datadog-agent-jncmj 3/3 Running 0 64s
datadog-cluster-agent-97655d49c-jf6lp 1/1 Running 0 6m30s
my-datadog-operator-667d4d6645-725j2 1/1 Running 0 17m
Deploying KEDA
Support to use the Cluster Agent as proxy was added in version 2.15 of KEDA, so that’s the minimum version that we need to deploy. We will deploy KEDA using the Helm chart:
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
helm install keda kedacore/keda --namespace keda --create-namespace --version=2.15.0
Check that the KEDA pods are running correctly:
kubectl get pods -n keda
NAME READY STATUS RESTARTS AGE
keda-admission-webhooks-79b9989f88-7g26p 1/1 Running 0 2m6s
keda-operator-fbc8b6c8f-84nqc 1/1 Running 1 (119s ago) 2m6s
keda-operator-metrics-apiserver-69dc6df9db-n8sxf 1/1 Running 0 2m6s
Give the KEDA Datadog scaler permissions to access the Cluster Agent metrics endpoint
The KEDA Datadog scaler will connect to the Cluster Agent through a Service Account, that will require enough permissions to access the Kubernetes metrics APIs.
For this example we will create a specific namespace for everything related to the KEDA Datadog scaler:
kubectl create ns datadog-keda
We will create a service account that will be used to connect to the Cluster Agent, a ClusterRole to read the external metrics API, and we will bind both.
Create the service account:
kubectl create sa datadog-metrics-reader -n datadog-keda
Create a ClusterRole that can at least read the Kubernetes metrics APIs:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: datadog-metrics-reader
rules:
- apiGroups:
- external.metrics.k8s.io
resources:
- '*'
verbs:
- get
- watch
- list
Create the ClusterRole by applying the definition above:
kubectl apply -f /path/to/your/datadog-cluster-role.yaml
Bind the ClusterRole with the previously created ServiceAccount:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: datadog-keda-crb
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: datadog-metrics-reader
subjects:
- kind: ServiceAccount
name: datadog-metrics-reader
namespace: datadog-keda
Create the ClusterRoleBinding by applying the definition above:
kubectl apply -f /path/to/your/datadog-cluster-role-binding.yaml
We will create a secret to hold the service account token that we will be using to connect to the Cluster Agent:
apiVersion: v1
kind: Secret
metadata:
name: datadog-metrics-reader-token
namespace: datadog-keda
annotations:
kubernetes.io/service-account.name: datadog-metrics-reader
type: kubernetes.io/service-account-token
Create it by applying the definition above:
kubectl apply -f /path/to/your/sa-token-secret.yaml
TriggerAuthentication for our Datadog Cluster Agent
We will define a secret and a corresponding TriggerAuthentication object to hold the configuration to connect to the Cluster Agent, so we can reuse it in several ScaledObject definitions if needed.
First, let’s create a Secret with the configuration of our Cluster Agent deployment:
kubectl create secret generic datadog-config -n datadog-keda --from-literal=authMode=bearer --from-literal=datadogNamespace=datadog --from-literal=unsafeSsl=true --from-literal=datadogMetricsService=datadog-cluster-agent-metrics-server
Then, let’s create a TriggerAuthentication object pointing to this configuration and the service account token:
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: datadog-trigger-auth
namespace: datadog-keda
spec:
secretTargetRef:
- parameter: token
name: datadog-metrics-reader-token
key: token
- parameter: datadogNamespace
name: datadog-config
key: datadogNamespace
- parameter: unsafeSsl
name: datadog-config
key: unsafeSsl
- parameter: authMode
name: datadog-config
key: authMode
- parameter: datadogMetricsService
name: datadog-config
key: datadogMetricsService
Apply the definition above:
kubectl apply -f /path/to/your/trigger-authentication.yaml
Create a Deployment to scale and a ScaleObject to define our scaling needs
We will be using NGINX and the NGINX Datadog integration to ensure we have traffic metrics in our Datadog account.
apiVersion: v1
data:
status.conf: |
server {
listen 81;
location /nginx_status {
stub_status on;
}
}
kind: ConfigMap
metadata:
name: nginx-conf
namespace: datadog-keda
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx
namespace: datadog-keda
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
creationTimestamp: null
labels:
app: nginx
annotations:
ad.datadoghq.com/nginx.check_names: '["nginx"]'
ad.datadoghq.com/nginx.init_configs: '[{}]'
ad.datadoghq.com/nginx.instances: |
[
{
"nginx_status_url":"http://%%host%%:81/nginx_status/"
}
]
spec:
containers:
- image: nginx
name: nginx
ports:
- containerPort: 80
- containerPort: 81
volumeMounts:
- mountPath: /etc/nginx/conf.d/status.conf
subPath: status.conf
readOnly: true
name: "config"
volumes:
- name: "config"
configMap:
name: nginx-conf
---
apiVersion: v1
kind: Service
metadata:
namespace: datadog-keda
name: nginxsvc
spec:
ports:
- name: default
port: 80
protocol: TCP
targetPort: 80
- name: status
port: 81
protocol: TCP
targetPort: 81
selector:
app: nginx
Create the NGINX deployment that we will be using in our example by applying the definition above:
kubectl apply -f /path/to/your/nginx-deployment.yaml
To notify the Cluster Agent that it needs to retrieve a specific metric from Datadog, we need to define a DatadogMetric object, specifying the always-active: true annotation to ensure the Cluster Agent retrieves the metric value, even though it is not registered in the Kubernetes API. We will use the requests per second metric:
apiVersion: datadoghq.com/v1alpha1
kind: DatadogMetric
metadata:
annotations:
external-metrics.datadoghq.com/always-active: "true"
name: nginx-hits
namespace: datadog-keda
spec:
query: sum:nginx.net.request_per_s{kube_deployment:nginx}
Create the DatadogMetric resource by applying the definition above:
kubectl apply -f /path/to/your/datadog-metric.yaml
You can check that the Cluster Agent is retrieving the metric correctly from Datadog with kubectl:
kubectl get datadogmetric -n datadog-keda
NAME ACTIVE VALID VALUE REFERENCES UPDATE TIME
nginx-hits True True 0.19999875128269196 53s
Finally, we will create a ScaledObject to tell KEDA to scale our NGINX deployment based on the number of requests per second:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: datadog-scaledobject
namespace: datadog-keda
spec:
scaleTargetRef:
name: nginx
maxReplicaCount: 3
minReplicaCount: 1
pollingInterval: 60
triggers:
- type: datadog
metadata:
useClusterAgentProxy: "true"
datadogMetricName: "nginx-hits"
datadogMetricNamespace: "datadog-keda"
targetValue: "2"
type: "global"
authenticationRef:
name: datadog-trigger-auth
Apply the definition above:
kubectl apply -f /path/to/your/datadog-scaled-object.yaml
You can check that KEDA is retrieving the metric value correctly from the Cluster Agent by checking the HorizontalPodAutoscaler object that it creates:
get hpa -n datadog-keda
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-datadog-scaledobject Deployment/nginx 133m/2 1 3 1 82s
Finally, to test that the NGINX deployment is scaling based on traffic, we will create some fake traffic to force the scaling event:
apiVersion: v1
kind: Pod
metadata:
name: fake-traffic
namespace: datadog-keda
spec:
containers:
- image: busybox
name: test
command: ["/bin/sh"]
args: ["-c", "while true; do wget -O /dev/null http://nginxsvc/; sleep 0.1; done"]
kubectl apply -f /path/to/your/fake-traffic.yaml
After a few seconds you will see the NGINX deployment scaling out:
kubectl get hpa,pods -n datadog-keda
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/keda-hpa-datadog-scaledobject Deployment/nginx 13799m/2 1 3 3 29m
NAME READY STATUS RESTARTS AGE
pod/fake-traffic 1/1 Running 0 4m35s
pod/nginx-bcb986cd7-8h6cf 1/1 Running 0 3m50s
pod/nginx-bcb986cd7-k47jx 1/1 Running 0 3m35s
pod/nginx-bcb986cd7-ngkp8 1/1 Running 0 170m
Summary
Enabling using the Cluster Agent as proxy to retrieve metrics for the KEDA Datadog scaler has multiple advantages. One of the most obvious ones is that the Cluster Agent will retrieve metrics from Datadog in batches, so the risk of reaching API rate limits is reduced.