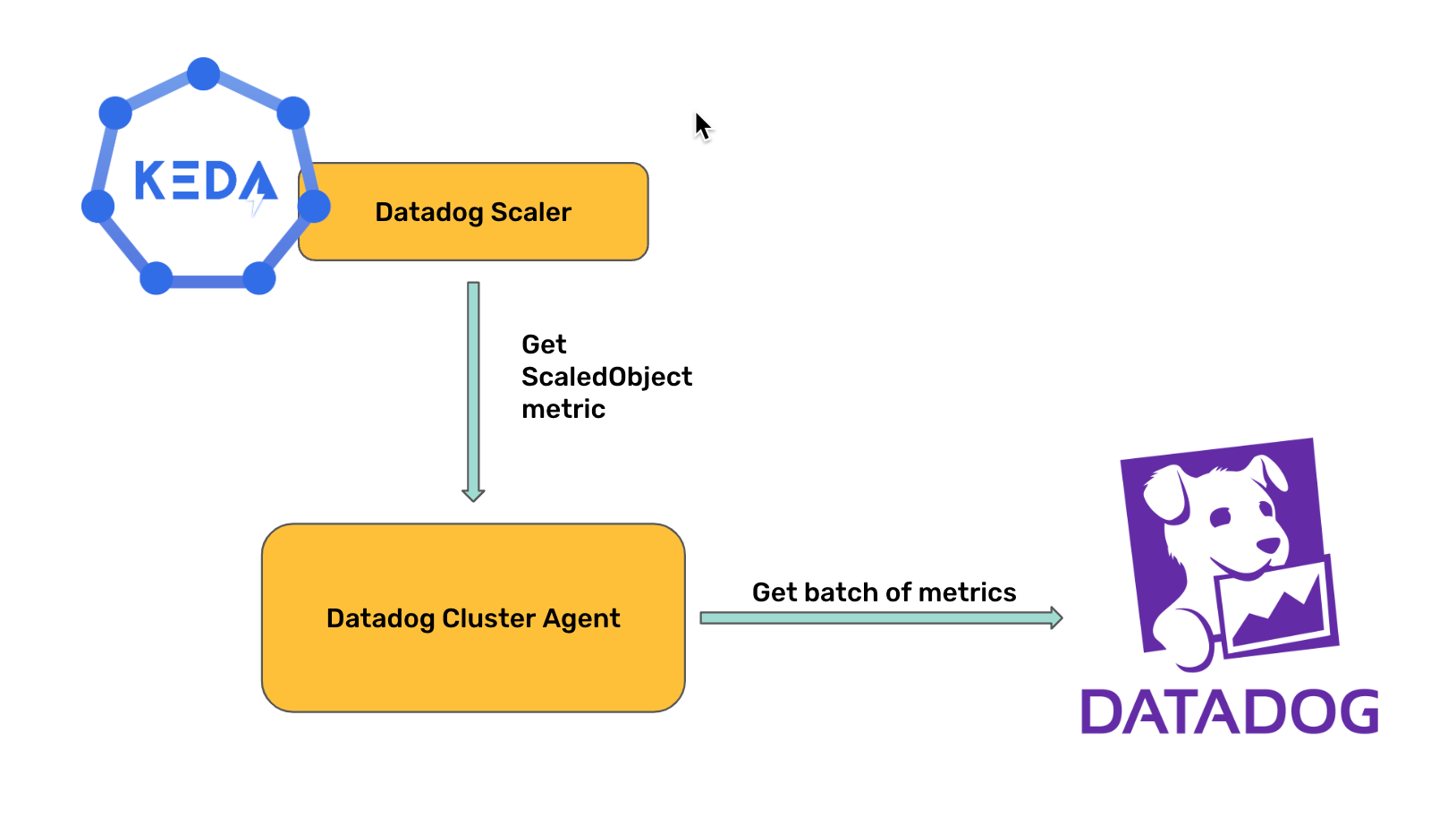
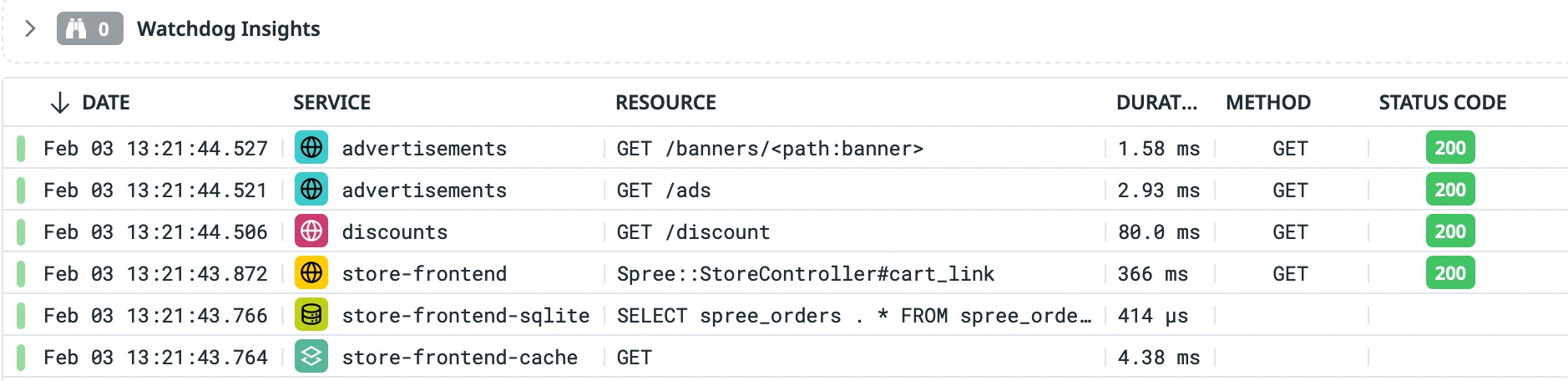
In February 2022 we introduced the availability of the Datadog KEDA scaler, allowing KEDA users to use Datadog metrics to drive their autoscaling events. This has been working well over the past two years, but it has a main issue, particularly when scaling the number of ScaledObjects that use the Datadog scaler. As the scaler uses the Datadog API to get metrics values, users may reach API rate limits as they scale their KEDA Datadog scaler usage.
For this reason, I decided to contribute again to the KEDA Datadog scaler for it to be able to use the Datadog Cluster Agent as proxy to gather the metrics, instead of polling the API directly. One of the benefits of this approach is that the Cluster Agent is able to batch the metrics requests to the API, reducing the risk of reaching API rate limits.
This post will be a step by step guide on how to set up both KEDA and the Datadog Cluster Agent to enable metrics gathering using the Cluster Agent as proxy. In this guide we will be using the Datadog Operator to deploy the Datadog Agent and Cluster Agent, but you can also use the Datadog Helm chart following the KEDA Datadog scaler documentation
Deploying Datadog
We start with a clean simple 1 node Kubernetes cluster.
First, we deploy the Datadog Operator using Helm To use the Cluster Agent as proxy for KEDA, at least version 1.8.0 of the Datadog Operator is needed:
In order to enable the Cluster Agent as proxy, we will deploy the Datadog Agent with the minimum configuration below:
apiVersion:datadoghq.com/v2alpha1kind:DatadogAgentmetadata:name:datadognamespace:datadogspec:global:kubelet:tlsVerify:false# This is only needed for self-signed certificatescredentials:apiSecret:secretName:datadog-secretkeyName:api-keyappSecret:secretName:datadog-secretkeyName:app-keyfeatures:externalMetricsServer:enabled:trueuseDatadogMetrics:trueregisterAPIService:falseoverride:clusterAgent:env:[{name:DD_EXTERNAL_METRICS_PROVIDER_ENABLE_DATADOGMETRIC_AUTOGEN,value:"false"}]
Deploy the Datadog Agent and Cluster Agent by applying the definition above:
kubectl apply -f /path/to/your/datadog-agent.yaml
You can check that the Node Agent and Cluster Agent pods are running correctly:
kubectl get pods -n datadog
NAME READY STATUS RESTARTS AGE
datadog-agent-jncmj 3/3 Running 0 64s
datadog-cluster-agent-97655d49c-jf6lp 1/1 Running 0 6m30s
my-datadog-operator-667d4d6645-725j2 1/1 Running 0 17m
Deploying KEDA
Support to use the Cluster Agent as proxy was added in version 2.15 of KEDA, so that’s the minimum version that we need to deploy. We will deploy KEDA using the Helm chart:
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
helm install keda kedacore/keda --namespace keda --create-namespace--version=2.15.0
Check that the KEDA pods are running correctly:
kubectl get pods -n keda
NAME READY STATUS RESTARTS AGE
keda-admission-webhooks-79b9989f88-7g26p 1/1 Running 0 2m6s
keda-operator-fbc8b6c8f-84nqc 1/1 Running 1 (119s ago) 2m6s
keda-operator-metrics-apiserver-69dc6df9db-n8sxf 1/1 Running 0 2m6s
Give the KEDA Datadog scaler permissions to access the Cluster Agent metrics endpoint
The KEDA Datadog scaler will connect to the Cluster Agent through a Service Account, that will require enough permissions to access the Kubernetes metrics APIs.
For this example we will create a specific namespace for everything related to the KEDA Datadog scaler:
kubectl create ns datadog-keda
We will create a service account that will be used to connect to the Cluster Agent, a ClusterRole to read the external metrics API, and we will bind both.
Create the service account:
kubectl create sa datadog-metrics-reader -n datadog-keda
Create a ClusterRole that can at least read the Kubernetes metrics APIs:
TriggerAuthentication for our Datadog Cluster Agent
We will define a secret and a corresponding TriggerAuthentication object to hold the configuration to connect to the Cluster Agent, so we can reuse it in several ScaledObject definitions if needed.
First, let’s create a Secret with the configuration of our Cluster Agent deployment:
To notify the Cluster Agent that it needs to retrieve a specific metric from Datadog, we need to define a DatadogMetric object, specifying the always-active: true annotation to ensure the Cluster Agent retrieves the metric value, even though it is not registered in the Kubernetes API. We will use the requests per second metric:
You can check that KEDA is retrieving the metric value correctly from the Cluster Agent by checking the HorizontalPodAutoscaler object that it creates:
get hpa -n datadog-keda
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-datadog-scaledobject Deployment/nginx 133m/2 1 3 1 82s
Finally, to test that the NGINX deployment is scaling based on traffic, we will create some fake traffic to force the scaling event:
After a few seconds you will see the NGINX deployment scaling out:
kubectl get hpa,pods -n datadog-keda
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/keda-hpa-datadog-scaledobject Deployment/nginx 13799m/2 1 3 3 29m
NAME READY STATUS RESTARTS AGE
pod/fake-traffic 1/1 Running 0 4m35s
pod/nginx-bcb986cd7-8h6cf 1/1 Running 0 3m50s
pod/nginx-bcb986cd7-k47jx 1/1 Running 0 3m35s
pod/nginx-bcb986cd7-ngkp8 1/1 Running 0 170m
Summary
Enabling using the Cluster Agent as proxy to retrieve metrics for the KEDA Datadog scaler has multiple advantages. One of the most obvious ones is that the Cluster Agent will retrieve metrics from Datadog in batches, so the risk of reaching API rate limits is reduced.
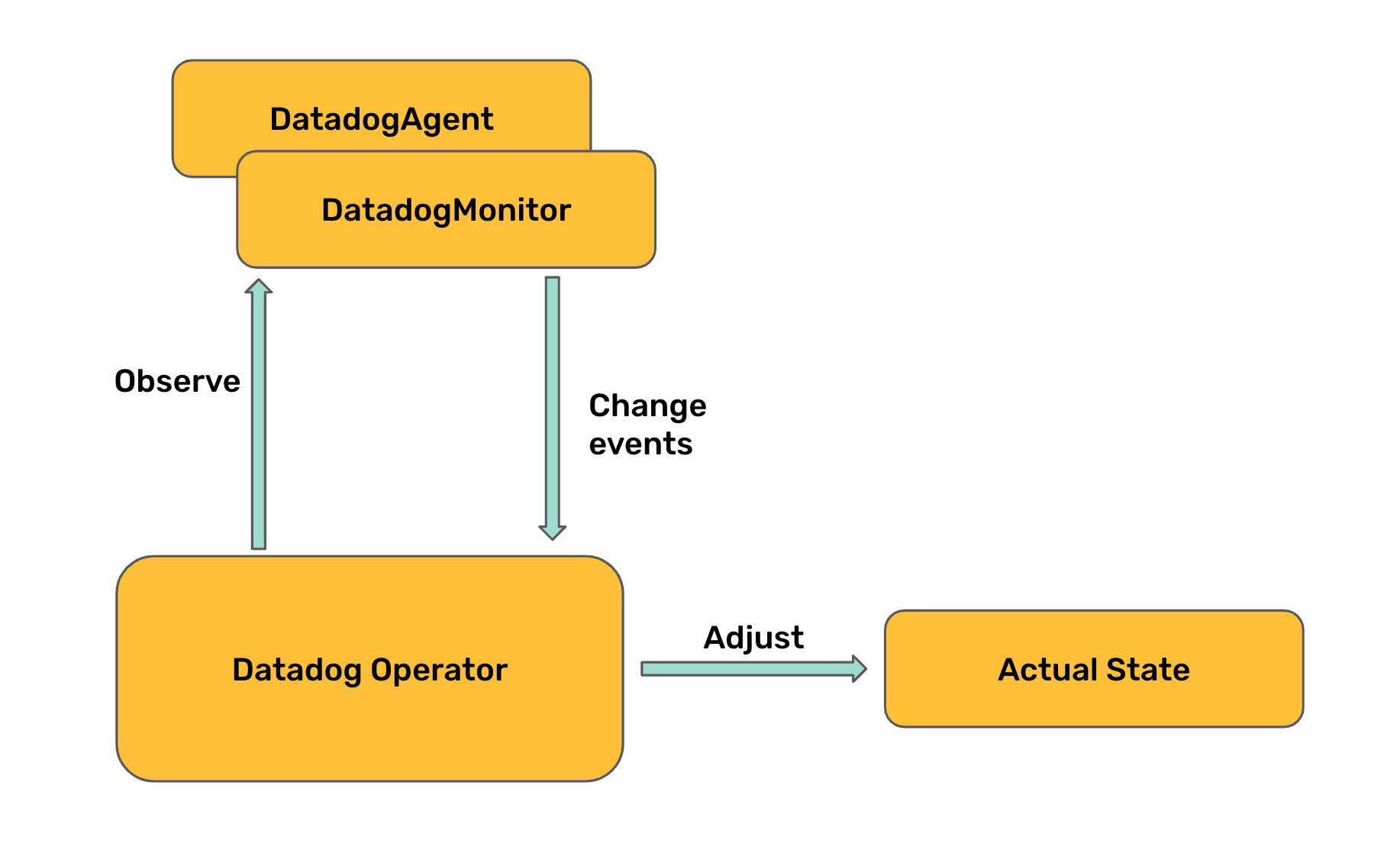
Kubernetes was designed from the very beginning as “API centric”. Almost everything in Kubernetes can be expressed as an API resource (usually as a YAML file) and kept on git with the rest of your infrastructure configuration. These resources are a way to express the desired state of your cluster.
Once these resources are applied to your cluster, there is a set of Kubernetes components called controllers that will apply the needed changes to the cluster to ensure that the actual state of the cluster is the desired state, following a true declarative model.
The success of the KRM is that this model can also be used to extend the Kubernetes API and to manage objects inside and outside the cluster in the same way. Datadog has created a set of new Kubernetes custom resources (CRDs) to manage Datadog cluster and in-app components.
In this post we’ll explain the Datadog related CRDs that are available, how to use them and why they are very useful if you are using Datadog to monitor your Kubernetes infrastructure and applications.
The Datadog Operator
The Datadog Operator is the Kubernetes controller that will manage the reconciliation loop for some Datadog related resources. The Datadog Operator, once deployed in a Kubernetes cluster, will watch the Kubernetes API for any changes related to these resources, and will make the needed changes in the cluster or in the Datadog API.
To deploy the Datadog Operator in your cluster you can use Helm:
The DatadogAgent is the resource to manage your Datadog agents deployments. Instead of having to craft a complex Helm values.yaml file, the idea behind using DatadogAgent is to describe what Datadog features are needed in a cluster, and the Datadog Operator will deploy the needed Kubernetes resources to fulfill those requirements.
In this example we have set the name of the cluster and we have referenced the secret with our Datadog keys. Then we have selected some options for both the Node Agent and the Cluster Agent.
In the case of the Node Agent, we have accepted self-signed certificates for the Kubelet. For the Cluster Agent we have enabled the external metrics server and the admission controllers.
Let’s apply this object:
kubectl apply -f datadogagent-basic.yaml
This creates a DatadogAgent resource that can be explored:
kubectl describe datadogagent datadog
You will see all the different Kubernetes resources that were created:
[...]
Events:
Type Reason Age From Message
-------------------------
Normal Create Secret 8m39s DatadogAgent default/datadog
Normal Create Service 8m39s DatadogAgent default/datadog-cluster-agent
Normal Create PodDisruptionBudget 8m39s DatadogAgent default/datadog-cluster-agent
Normal Create ServiceAccount 8m39s DatadogAgent default/datadog-cluster-agent
Normal Create ClusterRole 8m39s DatadogAgent /datadog-cluster-agent
[...]
These resources are created in a specific order, to make sure that all prerequisites for some of the resources are met.
In particular, it creates a Deployment for the Cluster Agent and a Daemonset for the Node Agent, with the right configuration options based on the chosen options:
kubectl get daemonset
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
datadog-agent 1 1 1 1 1 <none> 105m
kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
datadog-cluster-agent 1/1 1 1 106m
All the possible configuration options for the DatadogAgent resource are available in its documentation.
DatadogMonitor
DatadogMonitor is a resource that allows you to manage your Datadog Monitors using resource definitions that can be maintained with the rest of your cluster configuration.
This is very useful, as it allows you to review changes to your application or infrastructure alongside potential changes needed for the monitors that alert on them.
The DatadogMonitor resource is fairly simple. It includes a type and a query. The example above uses type “query alert”, that creates a Monitor that alerts on a specific Datadog query.
Let’s apply that resource:
kubectl apply -f datadogmonitor.yaml
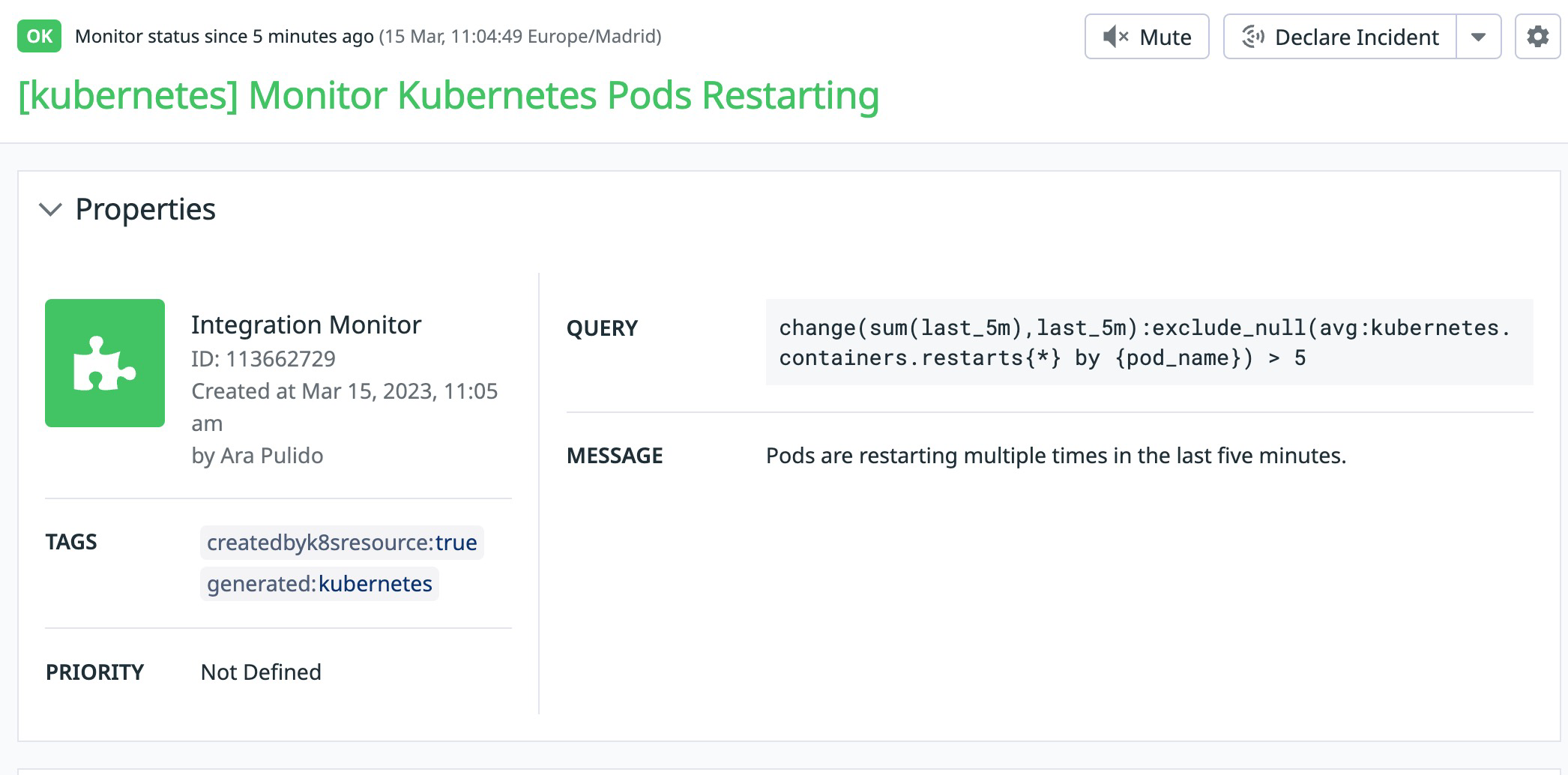
Once created, we can see the monitor being created in our Datadog account:
As any other Kubernetes resource, we can also have a look to the state of the resource using kubectl:
kubectl get datadogmonitor
NAME ID MONITOR STATE LAST TRANSITION LAST SYNC SYNC STATUS AGE
pods-restarting 113662729 OK 2023-03-15T10:06:49Z 2023-03-15T10:10:49Z OK 5m52s
You can find a set of examples for DatadogMonitor resources with their different monitor types in their git repository.
DatadogMetric
The Datadog Cluster Agent can also work as a Custom Metrics Server for Kubernetes. Meaning, you can use the metrics you have in Datadog to drive scaling your Kubernetes Deployments with the Horizontal Pod Autoscaler (HPA).
Once you’ve enabled the External Metrics Server in the Cluster Agent, you can create HPA resources that query a specific Datadog metric and set a target for that metric:
The Cluster Agent acts as the Kubernetes controller for DatadogMetric resources, so the Datadog Operator is not required in order to use those.
Once this resource is created, the Cluster Agent will update the value of that query using the Datadog API and will expose the result as a new metric in its External Metrics Server. This “new” metric can now be used in an HPA object. The name of this new metric will take the following pattern: datadogmetric@<namespace>:<datadogmetric_name>
So, for the example above, you could create an HPA object with the following specification:
The Kubernetes Design Model is a great way to adopt a declarative configuration approach for resources inside, but also outside the cluster.
Datadog extends the Kubernetes API with 3 new resources: DatadogAgent, DatadogMonitor, and DatadogMetric, that allow Datadog users to manage their Datadog configuration following the same Kubernetes model.
The Datadog Cluster Agent is a specialized Datadog Agent for Kubernetes clusters that implements features specific to Kubernetes and acts as a proxy between Node Agents and the Kubernetes API.
The Datadog Cluster Agent includes a Kubernetes MutatingAdmissionWebhook that is able to modify Kubernetes API requests before they are processed. This allows the Cluster Agent to change the definitions of Kubernetes resources with the goal of improving their observability.
In this post we will explain some of the improvements that are injected in our Kubernetes clusters.
Kubernetes Admission Controllers
Note: This section explains briefly what Kubernetes Admission Controllers are and how they work. If you already know this, feel free to skip this section)
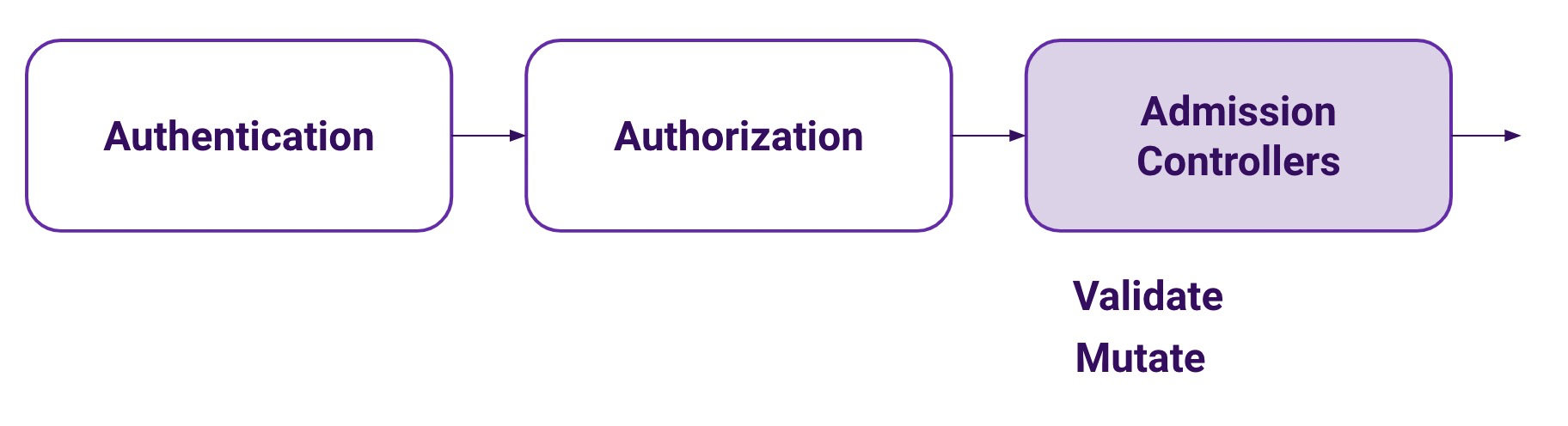
When a request is made to the Kubernetes API server it first goes through two phases:
Authentication. Is this request authenticated or not?
Authorization. Can this user perform this action against this type of resource in this particular namespace? This is mostly covered by RBAC.
But once the authenticated user is confirmed to be able to perform the selected action, it goes through a third phase: Admission Controllers.
Admissions Controllers are small pieces of code, embedded in the API server binary, that can further validate a request or even mutate it. There is a set of precompiled Admission Controllers that are enabled or disabled using an API server command line argument.
From all the Admission Controllers available, there are two that are a bit different. These are the ValidatingAdmissionWebhook and MutatingAdmissionWebhook. These allow for processes outside the API Server to validate or mutate API requests, as they are able to register as a webhook.
The Datadog Cluster Agent implements a webhook registered with the MutatingAdmissionWebhook.
The Cluster Agent MutatingAdmissionWebhook
We will explain how the webhook works using a sample application. You can reproduce all of the examples below following the instructions in this GitHub repository.
Enabling the MutatingAdmissionWebhook
The first thing that is needed is to enable the MutatingAdmissionWebhook, as it is not enabled by default. The official Datadog docs explain how to enable it depending on the method used to deploy the Datadog Agent.
Basic resource modifications made by the Cluster Agent
Let’s check some of the basic modifications that the Datadog MutatingAdmissionWebhook does to a basic Deployment.
We can see that it has opted-in being modified using the label admission.datadoghq.com/enabled: "true".
After applying this definition, checking the resource that was actually created in the cluster, we can see that there are some differences, as the request was mutated:
These environment variables are needed to get the right labeled metrics and traces to Datadog.
Before the Cluster Agent implemented this MutatingAdmissionWebhook, Datadog users needed to remember to add these environment variables themselves, cluttering their resources if they remembered, or not getting the most of Datadog, if they didn’t.
Autoinstrumentation library injection
But the most interesting feature in the MutatingAdmissionWebhook is the ability to automatically inject autoinstrumentation libraries into our pods and start getting traces into Datadog without having to modify our code or our pod definitions.
At the time of writing of this blog post, library injection was available for Javascript, Java, and Python. This section explains how it works for Python.
We take the same Deployment definition as the section above, but we add a new annotation to the pod template to enable library injection:
After creating the resource in our cluster, we can see that, aside from the environment variables, there are more differences in the created pod. Let’s dive in:
An emptyDir volume is added to the pod definition and a corresponding volume mount is added to the container:
The only thing this init container does is to copy a python file called sitecustomize.py into the volume mount /datadog-lib of the containers:
#!/bin/sh# This script is used by the admission controller to install the library from the# init container into the application container.cp sitecustomize.py "$1/sitecustomize.py"
Finally, there is a new environment variable in the main container that will force loading that Python module:
env:-name:PYTHONPATHvalue:/datadog-lib/
Let’s check the content of that module to understand what will happen when loading it:
importosimportsysdef_configure_ddtrace():# This import has the same effect as ddtrace-run for the current process.
importddtrace.bootstrap.sitecustomizebootstrap_dir=os.path.abspath(os.path.dirname(ddtrace.bootstrap.sitecustomize.__file__))prev_python_path=os.getenv("PYTHONPATH","")os.environ["PYTHONPATH"]="%s%s%s"%(bootstrap_dir,os.path.pathsep,prev_python_path)# Also insert the bootstrap dir in the path of the current python process.
sys.path.insert(0,bootstrap_dir)print("datadog autoinstrumentation: successfully configured python package")# Avoid infinite loop when attempting to install ddtrace. This flag is set when
# the subprocess is launched to perform the install.
if"DDTRACE_PYTHON_INSTALL_IN_PROGRESS"notinos.environ:try:importddtrace# noqa: F401
exceptImportError:importsubprocessprint("datadog autoinstrumentation: installing python package")# Set the flag to avoid an infinite loop.
env=os.environ.copy()env["DDTRACE_PYTHON_INSTALL_IN_PROGRESS"]="true"# Execute the installation with the current interpreter
try:subprocess.run([sys.executable,"-m","pip","install","ddtrace"],env=env)exceptException:print("datadog autoinstrumentation: failed to install python package")else:print("datadog autoinstrumentation: successfully installed python package")_configure_ddtrace()else:print("datadog autoinstrumentation: ddtrace already installed, skipping install")_configure_ddtrace()
The module basically runs pip install to install the ddtrace package and, once installed, imports the module that starts autoinstrumentation and adds it to the PYTHONPATH. This is the same module that is called when running ddtrace-run, the previous way to autoinstrument your Python applications with Datadog instrumentation libraries.
Once the MutatingAdmissionWebhook injects those libraries, we will start seeing traces coming into Datadog without any code modification:
Summary
Enabling the Datadog MutatingAdmissionController in a Datadog monitored Kubernetes cluster helps improve the observability of the deployed applications. One of the most useful features is the ability to automatically inject and configure the tracing instrumentation libraries, making the process of making your application observable easier than ever.
If you are a user of Datadog’s log management product, you may already be familiar with logs pipelines and processors and how they can help extract your logs relevant data, enhancing search and allowing you to edit logs to enrich them with additional data.
Pipelines are executed in order, meaning that the output log entry of a pipeline is the input of the next one, until there are no more enabled pipelines.
But what you may not know is that before a log entry goes through the different pipelines, there is an extra, special pipeline that processes the log entry if this comes in a JSON format, the JSON Preprocessing pipeline.
The JSON Preprocessing pipeline
There is a set of reserved attributes for logs at Datadog that are particularly important for log management and data correlation: date, host, service, status, traceid and message.
If the log entry is in JSON format, Datadog tries to parse those elements in the Preprocessing pipeline, before the rest of the pipelines parse the log entry. This pipeline cannot be disabled.
The attributes that will define those special parameters for your logs are predefined by Datadog. For example, if your JSON log has a host attribute, its value will be used as the host for this particular log entry.
If you are using the Datadog log agent or any of the default Datadog integrations, the log entries will come with the attributes that the Preprocessing pipeline accepts.
Changing the default attributes
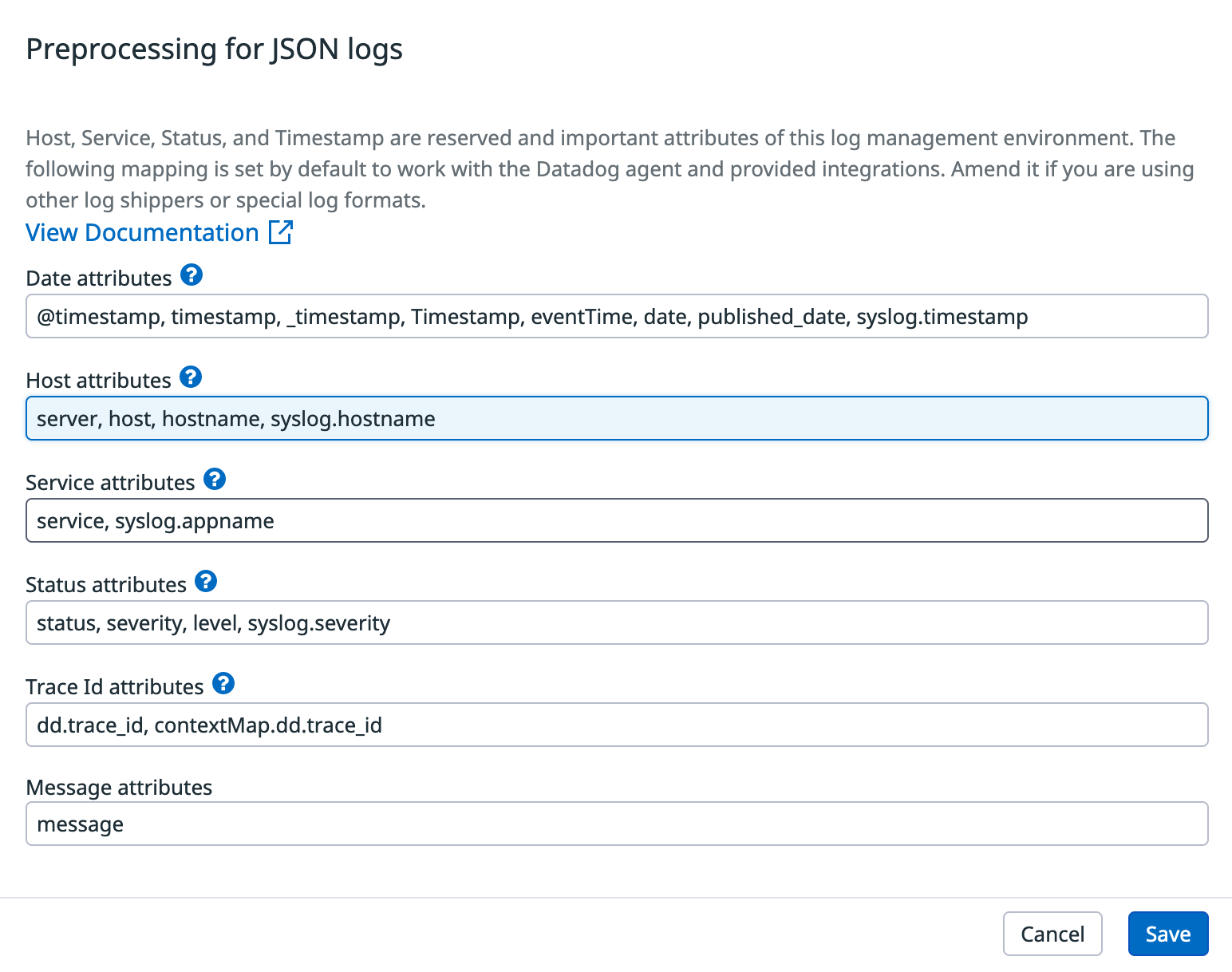
If you are sending your logs from log shippers with different attributes or with custom attributes you can modify the Preprocessing pipeline to make sure that Datadog uses those custom attributes.
For example, if you have log entries with a server attribute and you want to use that attribute as the host in Datadog, you can modify the default attributes in the Preprocessing pipeline.
You will get a modal window with the different attributes used for each of the parameters. They are ordered by precedence. For example, if your log entry has both a status and severity attributes, status will be used for “Status”, as it is the first one in that list.
You can add as many attributes as you need for each of the special parameters. In this example we are adding server to the host attributes:
New processed logs with a server attribute will parse its content as host going forward.
The special host attribute
All reserved attributes are special, but host is even more special.
All other reserved attributes can be remap after the preprocessing pipeline, and that’s why we have a date remapper, status remapper, etc.
The host attribute is assigned during the preprocessing pipeline and cannot be modified later on. So, if you need to modify the attribute that assigns the host name, make sure to modify the preprocessing pipeline attributes.
Summary
When defining your log pipelines in Datadog it is always useful to know that there is a special pipeline that comes first, the Preprocessing JSON logs pipeline. Users can modify the attributes that are taken into account when parsing log entries with this pipeline.
The OpenTelemetry Collector is a vendor agnostic agent to collect and export telemetry data. Datadog has an exporter available to receive traces and metrics from the OpenTelemetry SDKs and forward them to Datadog.
In this blog post we explain how to set this up in Heroku. If you want to check an end-to-end Python application sample, you can check this GitHub repository.
Adding the OTEL Collector Buildpack
The first thing that we need to do is to add the OTEL Collector to our Heroku application. I looked around and discovered this buildpack that adds the collector to your application. Unfortunately, this buildpack is a bit outdated, as in the latest versions of the collector the project has split into two distributions: core, and contrib, and most of the exporters are no longer available in the core distribution.
I have created a fork of the mentioned buildpack adding the possibility to deploy the contrib distribution instead. I have sent a PR upstream, and I will update this blog post once it is accepted. But, for now, we will be using my fork for this.
📝 EDIT: The PR has now been merged, so you can now used the original buildpack instead of my fork.
Add this buildpack to your application. The OTELCOL_CONTRIB environment variable tells the buildpack to use the Collector contrib distribution:
Configuring the OTEL Collector to send data to Datadog
In the root of your application, create a new otelcol and add your OTEL configuration as a config.yml file there. You can find an example of a working configuration for Datadog in the sample application git repository.
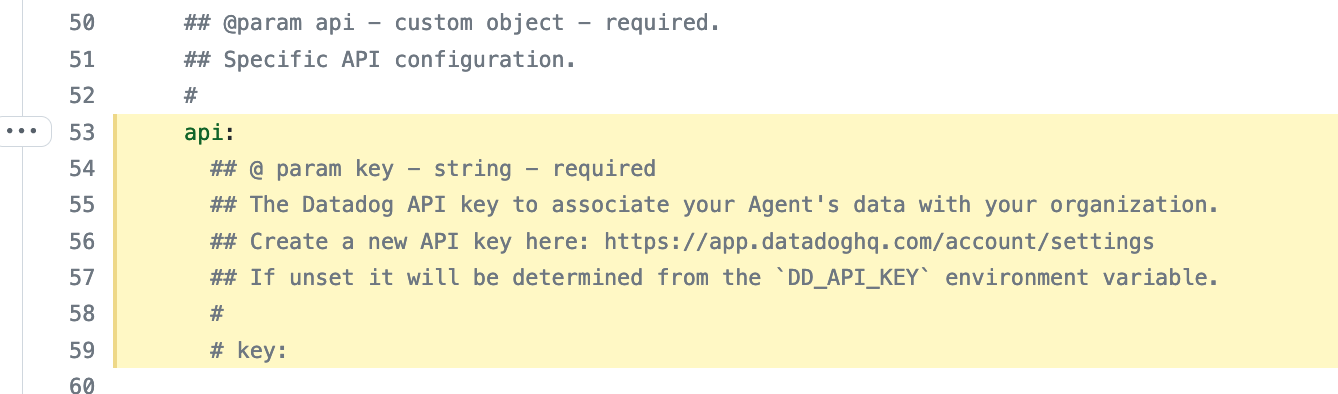
You should add your API key to that file under api.key:
Getting traces in Datadog
Once the buildpack has been added and the otelcol/config.yml pushed, the OTel Collector will start automatically when your dyno starts and will collect traces and metrics and send them to Datadog.
The following screenshot shows one of the traces from the sample application, collected by the OpenTelemetry Collector and pushed to Datadog:
Summary
Datadog maintains a Heroku Buildpack that deploys the Datadog Agent to gather telemetry (metrics, logs and traces) from your Heroku Dynos, but it is also possible to use the OpenTelemetry Collector to collect metrics and traces from your Heroku application and send them to Datadog through the Datadog exporter.